Scientists and engineers around the globe dream of employing biology to create new objects. The goal might be building replacement organs, electronic circuits, living houses, or cowborgs and carborgs (my favorites) that are composed of both standard electromechanical components and novel biological components. Whatever the dream, and however outlandish, we are getting closer every day.
Looking a bit further down the road, I would expect organs and tissues that have never before existed. For example, we might be able to manufacture hybrid internal organs for the cowborg that process rough biomass into renewable fuels and chemicals. Both the manufacturing process and the cowborg itself might utilize novel genetic pathways generated in DARPA's Living Foundries program. The first time I came across ideas like the cowborg was in David Brin's short story "Piecework". I've pondered this version of distributed biological manufacturing for years, pursuing the idea into microbrewing, and then to the cowborg, the economics of which I am now exploring with Steve Aldrich from bio-era.
Yet as attractive and powerful as biology is as a means for manufacturing, I am not sure it is powerful enough. Other ways that humans build things, and that we build things that build things, are likely to be part of our toolbox well into the future. Corrosion-resistant plumbing and pumps, for example, constitute very useful kit for moving around difficult fluids, and I wouldn't expect teflon to be produced biologically anytime soon. Photolithography, electrodeposition, and robotics, now emerging in the form of 3D printing, enable precise control over the position of matter, though frequently using materials and processes inimical to biology. Humans are really good at electrical and mechanical engineering, and we should build on that expertise with biological components.
Let's start with the now hypothetical cowborg. The mechanical part of a cowborg could be robotic, and could look like Big Dog, or perhaps simply a standard GPS-guided harvester, which comes standard with air conditioning and a DVD player to keep the back-up human navigation system awake. This platform would be supplemented by biological components, initially tanks of microbes, that turn raw feedstocks into complex materials and energy. Eventually, those tanks might be replaced by digestive organs and udders that produce gasoline instead of milk, where the artificial udders are enabled by advances in genetics, microbiology, and bioprinting. Realizing this vision could make biological technologies part of literally anything under the sun. In a simple but effective application along these lines, the ESA is already using "burnt bone charcoal" as a protective coating on a new solar satellite.
But there is one persistent problem with this vision: unless it is dead and processed, as in the case of the charcoal spacecraft coating, biology tends not to stay where you put it. Sometimes this will not matter, such as with many replacement transplant organs that are obviously supposed to be malleable, or with similar tissues made for drug testing. (See the recent Economist article, "Printing a bit of me", this CBS piece on Alexander Seifalian's work at University College London, and this week's remarkable news out of Anthony Atala's lab.) Otherwise, cells are usually squishy, and they tend to move around, which complicates their use in fabricating small structures that require precise positioning. So how do you use biology to build structures at the micro-scale? More specifically, how do you get biology to build the structures you want, as opposed to the structures biology usually builds?
We are getting better at directing organisms to make certain compounds via synthetic biology, and our temporal control of those processes is improving. We are inspired by the beautiful fabrication mechanisms that evolution has produced. Yet we still struggle to harness biology to build stuff. Will biological manufacturing ever be as useful as standard machining is, or as flexible as 3D printing appears it will be? I think the answer is that we will use biology where it makes sense, and we will use other methods where they make sense, and that in combination we will get the best of both worlds. What will it mean when we can program complex matter in space and time using a fusion of electromechanical control (machining and printing) biochemical control (chemistry and genetics)? There are several recent developments that point the way and demonstrate hybrid approaches that employ the 3D printing of biological inks that subsequently display growth and differentiation.

Above is a slide I used at the recent SynBERC retreat in Berkeley. On the upper left, Organovo is now shipping lab-produced liver tissue for drug testing. This tissue is not yet ready for use in transplants, but it does display all the structural and biochemical complexity of adult livers. A bit further along in development are tracheas from Harvard Biosciences, which are grown from patient stem cells on 3D-printed scaffolds (Claudia Castillo was the first recipient of a transplant like this in 2007, though her cells were grown on a cadaver windpipe first stripped of the donor's cells). And then we have the paper on the right, which really caught my eye. In that publication, viruses on a 3D woven substrate were used to reprogram human cells that were subsequently cultured on that substrate. The green cells above, which may not look like much, are the result of combining 3D fabrication of non-living materials with a biological ink (the virus), which in combination serve to physically and genetically program the differentiation and growth of mammalian cells, in this case into cartilage. That's pretty damn cool.
Dreams of building with biology
Years ago, during the 2003 "DARPA/ISAT Synthetic Biology Study", we spent considerable time discussing whether biology could be used to rationally build structures like integrated circuits. The idea isn't new: is there a way to get cells to build structures at the micro- or nano-scale that could help replace photolithography and other 2D patterning techniques used to build chips? How can humans make use of cells -- lovely, self-reproducing factories -- to construct objects at the nanometer scale of molecules like proteins, DNA, and microtubules?
Cells, of course, have dimensions in the micron range, and commercial photolithography was, even in 2003, operating at about the 25 nanometer range (now at about 15 nm). The challenge is to program cells to lay down structures much smaller than they are. Biology clearly knows how to do this already. Cells constantly manufacture and use complex molecules and assemblies that range from 1 to 100 nm. Many cells move or communicate using extensions ("processes") that are only 10-20 nanometers in width but tens microns in length. Alternatively, we might directly use synthetic DNA to construct a self-assembling scaffold at the nano-scale and then build devices on that scaffold using DNA-binding proteins. DNA origami has come a long way in the last decade and can be used to build structures that span nanometers to microns, and templating circuit elements on DNA is old news. We may even soon have batteries built on scaffolds formed by modified, self-assembling viruses. But putting all this together in a biological package that enables nanometer-scale control of fabrication across tens of centimeters, and doing it as well as lithography, and as reproducibly as lithography, has thus far proved difficult.
Conversely, starting at the macro scale, machining and 3D printing work pretty well from meters down to hundreds of microns. Below that length scale we can employ photolithography and other microfabrication methods, which can be used to produce high volumes of inexpensive objects in parallel, but which also tend to have quite high cost barriers. Transistors are so cheap that they are basically free on a per unit basis, while a new chip fab now costs Intel about $10 billion.
My experiences working on different aspects of these problems suggest to me that, eventually, we will learn to exploit the strengths of each of the relevant technologies, just as we learn to deal with their weaknesses; through the combination of these technologies we will build objects and systems that we can only dream of today.
Squishy construction
Staring through a microscope at fly brains for hours on end provides useful insights into the difference between anatomy and physiology, between construction and function. In my case, those hours were spent learning to find a particular neuron (known as H1) that is the output of the blowfly motion measurement and computation system. The absolute location of H1 varies from fly to fly, but eventually I learned to find H1 relative to other anatomical landmarks and to place my electrode within recording range (a few tens of microns) on the first or second try. It's been long known that the topological architecture (the connectivity, or wiring diagram) of fly brains is identical between individuals of a given species, even as the physical architecture (the locations of neurons) varies greatly. This is the difference between physiology and anatomy.
The electrical and computational output of H1 is extremely consistent between individuals, which is what makes flies such great experimental systems for neurobiology. This is, of course, because evolution has optimized the way these brains work -- their computational performance -- without the constraint that all the bits and pieces must be in exactly the same place in every brain. Fly brains are constructed of squishy matter, but the computational architecture is quite robust. Over the last twenty years, humans have learned to grow various kinds of neurons in dishes, and to coax them into connecting in interesting ways, but it is usually very hard to get those cells to position themselves physically exactly where you want them, with the sort of precision we regularly achieve with other forms of matter.
Crystalline construction
The first semiconductor processing instrument I laid hands on in 1995 was a stepper. This critical bit of kit projects UV light through a mask, which contains the image of a structure or circuit, onto the surface of a photoresist-covered silicon wafer. The UV light alters the chemical structure of the photoresist, which after further processing eventually enables the underlying silicon to be chemically etched in a pattern identical to the mask. Metal or other chemicals can be similarly patterned. After each exposure, the stepper automatically shifts the wafer over, thereby creating an array of structures or circuits on each wager. This process enables many copies of a chip to be packed onto a single silicon wafer and processed in parallel. The instruments on which I learned to process silicon could handle ~10 cm diameter wafers. Now the standard is about 30 cm, because putting more chips on a wafer reduces marginal processing costs. But it isn't cheap to assemble the infrastructure to make all this work. The particular stepper I used (this very instrument, as a matter of fact), which had been donated to the Nanofabrication Facility at Cornell and which was ancient by the time I got to it, contained a quartz lens I was told cost about $1 million all by itself. The kit used in a modern chip fab is far more expensive, and the chemical processing used to fabricate chips is quite inimical to cells. Post-processing, silicon chips can be treated in ways that encourages cells to grow on them and even to form electrical connections, but the overhead to get to that point is quite high.
Arbitrary construction
The advent of 3D printers enables the reasonably precise positioning of materials just about anywhere. Depending on how much you want to spend, you can print with different inks: plastics, composites, metals, and even cells. This lets you put stuff where you want it. The press is constantly full of interesting new examples of 3D printing, including clothes, bone replacements, objects d'art, gun components, and parts for airplanes. As promising as all this is, the utility of printing is still limited by the step size (the smallest increment of the position of the print head) and the spot size (the smallest amount of stuff the print head can spit out) of the printer itself. Moreover, printed parts are usually static: once you print them, they just sit there. But these limitations are already being overcome by using more complex inks.
Hybrid construction
If the ink used in the printer has the capacity to change after it gets printed, then you have introduced a temporal dimension into your process: now you have 4D printing. Typically, 4D printing refers to objects whose shape or mechanical properties can be dynamically controlled after construction, as with these 3D objects that fold up after being printed as 2D objects. But beyond this, if you combine squishy, crystalline, and arbitrary construction, you get a set of hybrid construction techniques that allows programming matter from the nanoscale to the macroscale in both time and space.
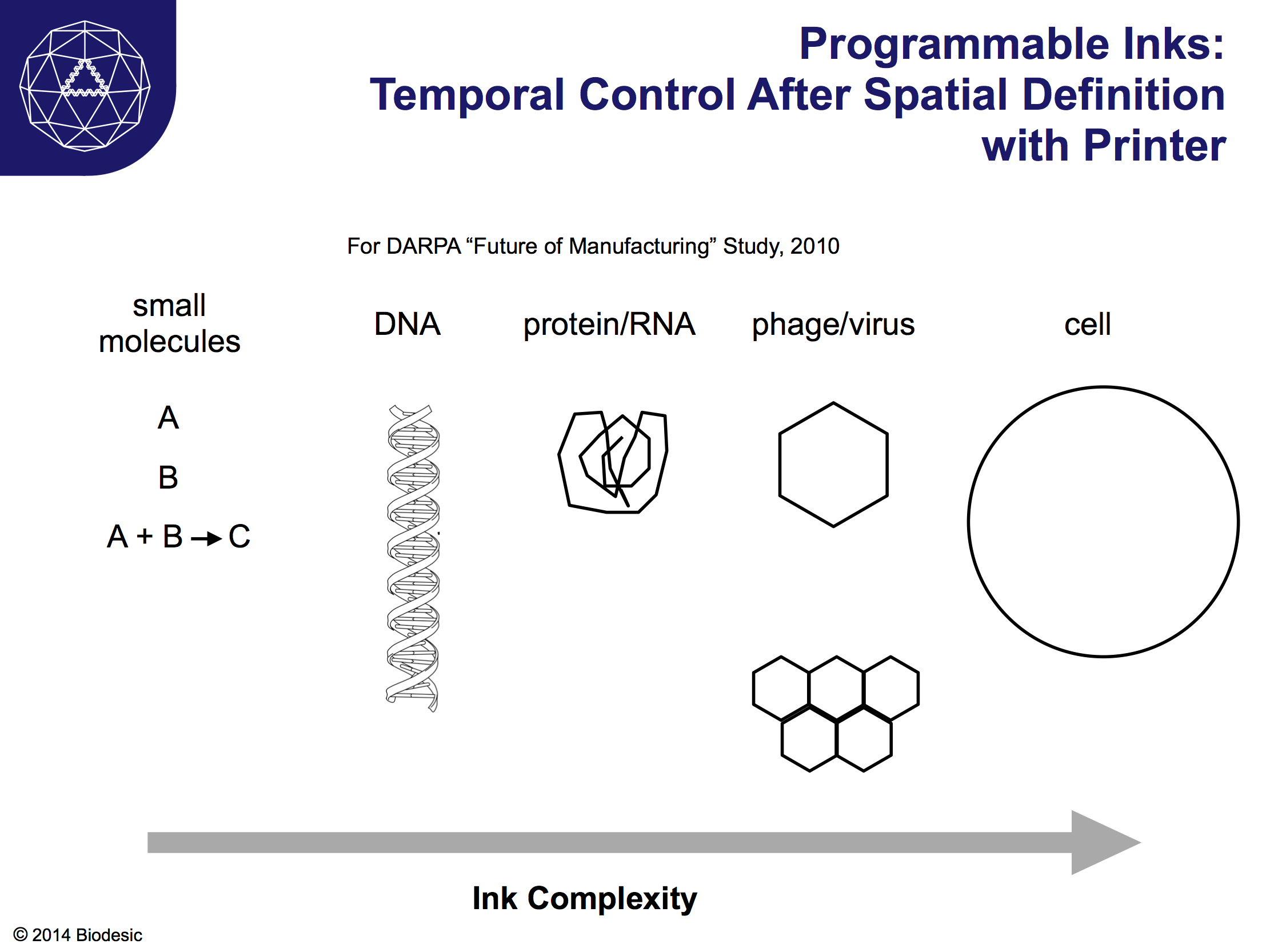
Above is a slide from a 2010 DARPA study on the Future of Manufacturing, from a talk in which I tried to articulate the utility of mashing up 3D printing and biotech. We have already seen the first 3D printed organs, as described earlier. Constructed using inks that contain cells, even the initial examples are physiologically similar to natural organs. Beyond tracheas, printed or lab-growth organs aren't yet ready for general use as transplants, but they are already being used to screen drugs and other chemicals for their utility and toxicity. Inks could also consist of: small molecules (i.e. chemicals) that react with each other or the environment after printing; DNA and proteins that serve structural, functional (say, electronic), or even genetic roles after printing; viruses that form structures or are that are intended to interact biologically with later layers; cells that interact with each other or follow some developmental program defined genetically or by the substrate, as demonstrated in principle by the cartilage paper above.
The ability to program the three-dimensional growth and development of complex structures will have transformative impacts throughout our manufacturing processes, and therefore throughout our economy. The obvious immediate applications include patient-specific organs and materials such as leather, bone, chitin, or even keratin (think vat-grown ivory), that are used in contexts very different than we are used to today.
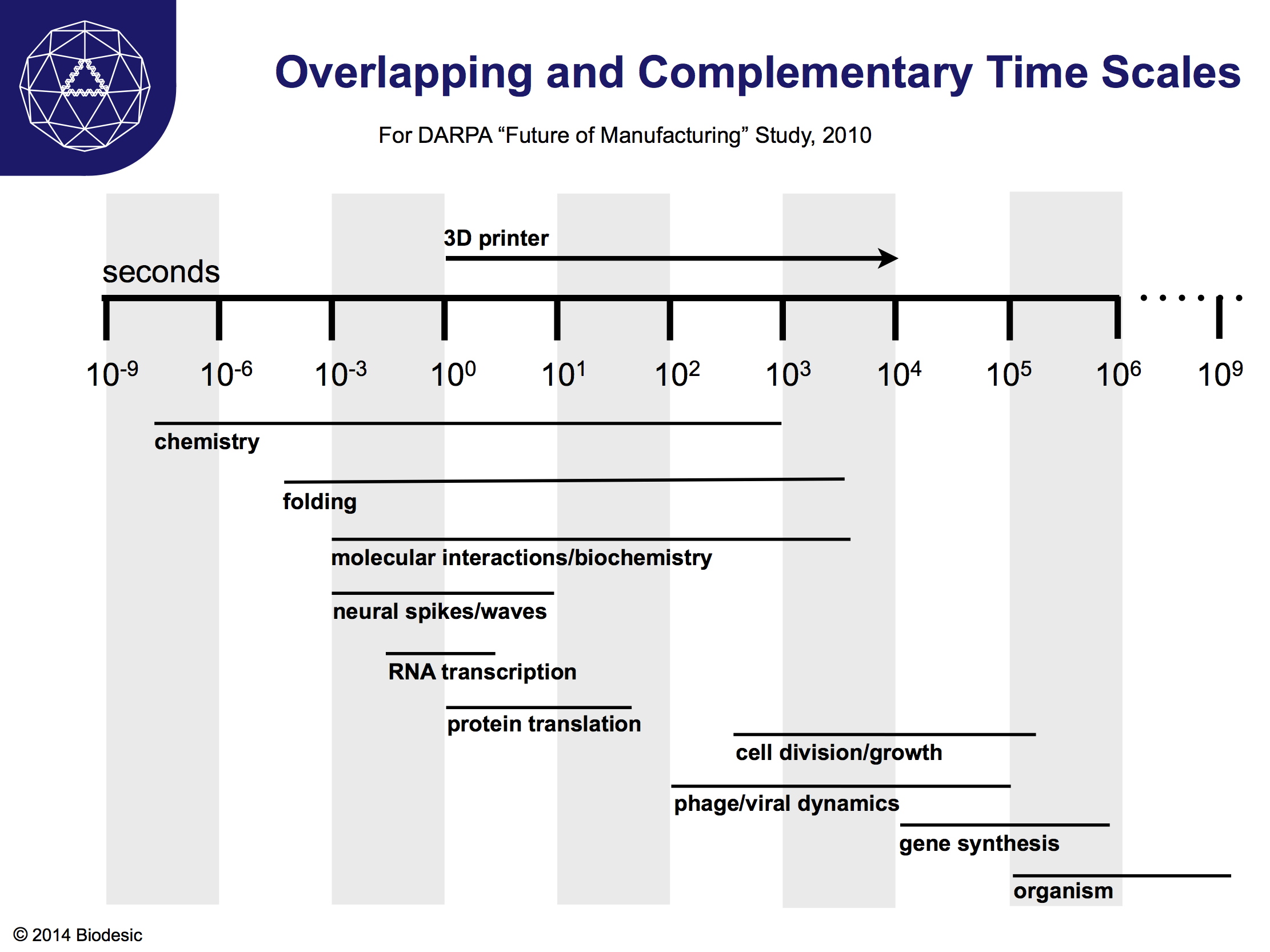
It is hard to predict where this is going, of course, but any function we now understand for molecules or cells can be included in programmable inks. Simple 2-part chemical reactions will eventually be common in inks, eventually transitioning to more complex inks containing multiple reactants, including enzymes and substrates. Eventually, programmable printer inks will employ the full complement of genes and biochemistry present in viruses, bacteria, and eukaryotic cells. Beyond existing genetics and biochemistry, new enzymes and genetic pathways will provide materials we have never before laid hands on. Within DARPA's Living Foundries program is the 1000 Molecules program, which recently awarded contracts to use biology to generate "chemical building blocks for accessing radical new materials that are impossible to create with traditional petroleum-based feedstocks".
Think about that for a moment: it turns out that of the entire theoretical space of compounds we can imagine, synthetic chemistry can only provide access to a relatively small sample. Biology, on the other hand, in particular novel systems of (potentially novel) enzymes, can be programmed to synthesize a much wider range of compounds. We are just learning how to design and construct these pathways; the world is going to look very different in ten years' time. Consequently, as these technologies come to fruition, we will learn to use new materials to build objects that may be printed at one length scale, say centimeters, and that grow and develop at length scales ranging from nanometers to hundreds of meters.
Just as hybrid construction that combines the features of printers and inks will enable manufacturing on widely ranging length scales, so will it give us access to a wide range of time scales. A 3D printer presently runs on fairly understandable human time scales of seconds to hours. For the time being, we are still learning how to control print heads and robotic arms that position materials, so they move fairly slowly. Over time, the print head will inevitably be able to move on time scales at least as short as milliseconds. Complex inks will then extend the reach of the fabrication process into the nanoseconds on the short end, and into the centuries on the long end.

I will be the first to admit that I haven't the slightest idea what artifacts made in this way will do or look like. Perhaps we will build/grow trees the size of redwoods that produce fruit containing libations rivaling the best wine and beer. Perhaps we will build/grow animals that languidly swim at the surface of the ocean, extracting raw materials from seawater and photosynthesizing compounds that don't even exist today but that critical to the future economy.
These examples will certainly prove hopelessly naive. Some problems will turn out to be harder than they appear today, and other problems will turn out to be much easier than they appear today. But the constraints of the past, including the oft-uttered phrase "biology doesn't work that way", do not apply. The future of engineering is not about understanding biology as we find it today, but rather about programming biology as we will build it tomorrow.
What I can say is that we are now making substantive progress in learning to manipulate matter, and indeed to program matter. Science fiction has covered this ground many times, sometimes well, sometimes poorly. But now we are doing it in the real world, and sketches like those on the slides above provide something of a map to figure out where we might be headed and what our technical capabilities will be like many years hence. The details are certainly difficult to discern, but if you step back a bit, and let your eyes defocus, the overall trajectory becomes clear.
This is a path that John von Neumann and Norbert Wiener set out on many decades ago. Physics and mathematics taught us what the rough possibilities should be. Chemistry and materials science have demonstrated many detailed examples of specific arrangements of atoms that behave physically in specific ways. Control theory has taught us both how organisms behave over time and how to build robots that behave in similar ways. Now we are learning to program biology at the molecular level. The space of the possible, of the achievable, is expanding on a daily basis. It is going to be an interesting ride.









{kind=link}